
Databases have become very valuable since they are used in managing companies’ data. If you look back just 30 years ago, people used to store data on paper, magnetic tape, or somewhere else. If you are creating and consuming smaller data amounts on a per capita basis, it will allow you to store, manage, and access it easily. Let us know what is Data Base Sharding in this blog post.
But, at present data is telling a totally different story. We all know how necessary and ubiquitous Smartphones have become today. The apps on Smartphones contain an increased amount of data. It has put huge stress on database clusters because of the need to handle larger amounts of traffic. Multiple websites & services receive a lot of visits each week. So, it becomes difficult to handle the huge volume of traffic once it reaches the database cluster. The solution to this problem could be sharding. Let’s learn what database sharding is.
What is Data base Sharding?
Sharding is a procedure to split one dataset across many databases. While people can store this on several machines, it lets larger datasets be split into smaller chunks. Then, people need to store them in many data nodes to boost the system’s total storage capacity.
When a sharded database distributes the data across multiple machines, it will be capable of handling more requests than a single machine. This type of scaling is called horizontal scaling or scale-out because extra nodes are brought on to share the load. It allows for near-limitless scalability, letting you handle large data & huge workloads. Vertical scaling means increasing a server’s or machine’s power via a more powerful CPU, increased RAM, or increased storage capacity.
Need For Data Base Sharding:
Suppose there is a big database whose sharding still hasn’t been done. For instance, a college has a database where it maintains records & stats of all students (from last till now). Suppose the number is one lakh, which is too big to handle. Now, if you want to find a student, you need to do around 100,000 transactions each time to find him or her from this huge database. And it is going to be very expensive. Dividing the records of students based on every year helps you find the stats and records of any student. By doing this, you will be able to divide this huge database into 1000-5000 student records in each data shard.
Sharding makes the database much more manageable and reduces transaction costs by a huge factor. That is why you will need Sharding.
Database sharding isn’t available for free with any distributed architecture. In setting up shards, complexity & overhead are there to maintain the data on each shard & route requests across those shards. Before knowing about this, consider if any alternative solution works for you.
Vertical Scaling:
Once you upgrade your machine, you are able to scale it vertically without the technique’s complexity.
Solutions that you can try are — upgrade your CPU, add RAM, and increase the storage available to the database. These solutions don’t need you to change the design of your database architecture or application.
Specialized Services Or Databases:
Based on the use case, you can easily shift a subset of the burden onto other providers or a separate database. For instance, you can move file storage directly to a cloud provider like Amazon S3. A data warehouse or specialized services are able to handle analytics or full-text search.
Replication:
When the data workload is primarily read-focused, replication will boost read performance & availability. Besides, it avoids the complexity of database sharding. You can increase read performance by spinning up extra database copies via load balancing or geo-located query routing. But on write-focused workloads, there is complexity because you have to copy every write to every replicated node.
When a core application database contains a huge amount of data, it will need high read & high write volume. If you have particular availability requirements, you can get help from this sharded database. Now, let’s learn the benefits and drawbacks of sharding.
Benefits Of Data Base Sharding:
The advantages of sharding are as follows:
Improved Scalability:
Due to sharding, it becomes possible for the systems to add more servers or nodes as the data grows to scale horizontally. Thus, the capacity of the system is improved, and it becomes able to handle large data volumes & requests.
Increased Performance:
This process splits the data across multiple servers or nodes. It helps to reduce the load on every node or server. Thus, you can get better performance from the system. Therefore, the response times will be faster, and you will get better throughput.
Fault Tolerance:
Even if one or more nodes or servers fail, the system will keep functioning, as sharding offers a degree of fault tolerance. The reason is that data replication is seen across many nodes or servers. If a server fails, others keep serving the requests.
Reduced Costs:
Sharding lets the system scale horizontally. As a result, it becomes more cost-effective than vertical scaling by upgrading hardware. The reason is that you can perform horizontal scaling with the help of commodity hardware. It is less costlier than high-end servers.
These are all the possible benefits of Sharding. Now, let’s learn about its drawbacks.
Disadvantages Of Sharding:
You should know that this process has many disadvantages, namely overhead in the complexity of administration, & enhanced infrastructure costs.
Query Overhead:
Every sharded database needs to have a separate machine or service that helps to analyze how to route a querying operation to the appropriate shard. It introduces extra latency on each operation. Whether the data necessary for the query is horizontally partitioned across many shards, the router should query each shard. After that, it combines the results together. Because of this, a simple operation can become expensive, resulting in slowing down response times.
Complexity Of Administration:
The database server needs upkeep & maintenance with one unsharded database. Extra service nodes exist to maintain on top of managing the shards themselves with each sharded database. If replication is being used, you need to mirror data updates across every replicated node. Above all, you should know that a sharded database can be a more complex system that needs more administration.
Increased Infrastructure Costs:
Sharding needs extra machines & computing power over a single database server. Every extra shard has higher costs, while sharding lets your database grow beyond a single machine’s limits. The cost of a distributed database system may be significant when it misses the proper optimization.
After knowing about the benefits and drawbacks, you should know how it works.
How Does Data Base Sharding Work?
When it comes to sharding a database, you need to know the answer to some basic questions. These will help you to determine your implementation.
You should know first how the data is going to be distributed across shards. Behind any sharded database, it is the most basic question. The answer to this question has effects on both performance & maintenance.
Second, you need to know what types of queries will be routed across shards. When you see that the workload is read operations, the replicating data becomes a lot more effective at increasing performance. You even might not require sharding at all. A primarily write-based or mixed read-write workload will need a different architecture.
At last, you need to know how many shards need to be maintained. If you have sharded a database, you have to split the data again among different shards. After that, you may have to create new shards. Based on the data split, the process might be on the costlier side. So, this process needs to be considered ahead of time.
Difference Between Sharding And Partitioning:
Sharding & partitioning break up a huge database into smaller databases. But you can find a difference between these two processes.
Once the database is sharded, you can split the data in the new tables across several systems. But it doesn’t happen with partitioning. It groups the data subsets within a single database instance.
Sharding Architectures And Types:
Although there exist several sharding methods, four types are considered here—
- ranged/dynamic sharding,
- algorithmic/hashed sharding,
- entity/relationship-based sharding, and
- geography-based sharding.
Ranged/dynamic Sharding:
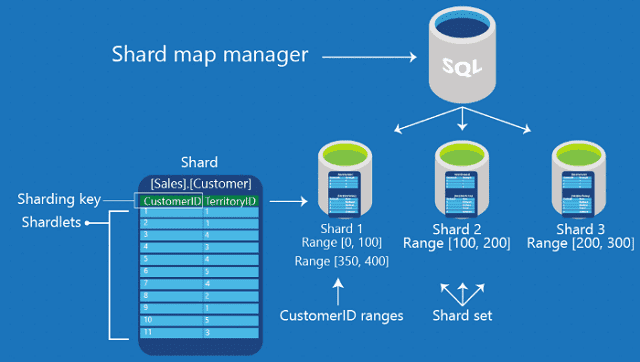
This type of sharding usually takes a field on the record as input. It allocates the record to the right shard depending on a predefined range. In this case, a lookup table or service should exist for all queries or writes. We know the shard key as the field on which the range is based. Shard keys are vital in making this process effective. If you choose a wrong shard key, it will cause unbalanced shards, resulting in reduced performance. Choosing an effective shard key will allow for queries to be targeted to the lowest shard number.
An effective shard key’s two key attributes are high cardinality & well-distributed frequency.
- Cardinality indicates the number of possible values of the specific key. When a shard key has three possible values, the maximum number of shards is three.
- Frequency hence indicates data’s distribution along the possible values. Suppose 95% of records occur with one shard key value. Then, all these records are allocated to one shard because of this hotspot. You can consider these attributes while choosing a shard key.
This sharding is simple to understand, and its effectiveness relies heavily on how much a shard key and the selection of appropriate ranges is available. You should know that the lookup service may also be a bottleneck, though the amount of data is small, which isn’t the problem in this case.
Advantages:
- Easy to implement
- The algorithm is simple as different shards contain identical schema to each other, and the original database.
Disadvantages:
- It can produce database hotspots because data is sometimes unevenly distributed and
- Selecting a wrong shard key may generate unbalanced shards & adversely impact performance.
Algorithmic/hashed Sharding:
This type of sharding takes a record as input. Then, a hash function or algorithm will be applicable to this, which produces a hash value or output. After that, it is used to allocate every record to the appropriate shard.
Any subset of values can be taken by the function on the record as inputs. Using the modulus operator with the number of shards is the easiest instance of a hash function, which is as follows:
Hash Value = ID % Number of Shards
It is like the previous type of sharding, where a set of fields indicates the record’s location in a given shard. Hashing the inputs lets you split even more across shards, though no suitable shard key is there. Hence, you don’t have to maintain any lookup tables. But it has some disadvantages.
For multiple records, query operations will be split across many shards. The ranged sharding can reflect the data’s natural structure across shards. However, hashed sharding disregards the meaning of the data. It is reflected in a boosted broadcast operation occurrence.
You should know that resharding is costlier. If there is any update to the shard numbers, you have to rebalance all shards to move around records. It will be challenging when you try to avoid a system outage.
Entity-/relationship-based Sharding:
The main purpose of this sharding is to keep related data together on one physical shard. Related data is distributed in a relational database across many different tables. You can use PostgreSQL, MySQL, or SQL Server as a relational database. Suppose there is a shopping database with people & their payment methods. In this case, every user has an individual set of payment methods that are connected tightly with that user. If you keep related data together on the same shard, it will decrease the need for broadcast operations to enhance performance.
Geography-based Sharding:
Its task is also similar to the previous one, it keeps the related data together on a single shard, but the data will be related to geography. In this ranged sharding, the shard key is available with the geographic informationgeo-located & shards are geo-located.
Suppose there is a dataset containing many records. Every record has a “country” field. Once you generate a shard for every region or nation, it is possible to boost the entire performance & reduce system latency. You also have to store the correct data on the shard. It is one of the easiest examples. Several ways exist through which you are able to allocate your shards.
The Bottom Line:
In this article, we have discussed several important things about sharding, like its definition, when you need to use it, and different sharding architectures. In simple words, it can be said that sharding is a perfect solution for apps with large data requirements & high-volume read/write workloads. But we can say that it has extra complexity. In this case, you are required to consider if the advantages outweigh the costs or if you find an easier solution before implementing this.
Frequently Asked Questions
What do you mean by sharding?
It is a database partitioning that is used to separate large databases into smaller parts that can be managed more easily. People call these smaller parts data shards. It indicates “a small part of a whole.”
What is the concept of sharding in blockchain systems?
This technique is used to split a blockchain up into smaller blockchains in the blockchain industry to allow it to handle more transactions.
What are sharding keys?
The “shard key” is used for distributing documents of any certain collection across all the shards.





